

Text-Independent Algorithm for Source Printer Identification Based on Ensemble Learning
Because of the widespread availability of low-cost printers and scanners, document forgery has become extremely popular. Watermarks or signatures are used to protect important papers such as certificates, passports, and identification cards. Identifying the origins of printed documents is helpful for criminal investigations and also for authenticating digital versions of a document in today’s world. Source printer identification (SPI) has become increasingly popular for identifying frauds in printed documents. This paper provides a proposed algorithm for identifying the source printer and

A Framework for Democratizing Open-Source Decision-Making using Decentralized Autonomous Organization
The open Source Software (OSS) became the backbone of the most heavily used technologies, including operating systems, cloud computing, AI, Blockchain, Bigdata Systems, IoT, and many more. Although the OSS individual contributors are the primary power for developing the OSS projects, they do not contribute to the OSS project's decisionmaking as much as their contributions in the OSS Projects development. This paper proposes a framework to democratize the OSS Project's decision-making using a blockchain-related technology called Decentralized Autonomous Organization (DAO). Using DAO

Detection and Prediction of Future Mental Disorder From Social Media Data Using Machine Learning, Ensemble Learning, and Large Language Models
Social media platforms are used widely by all people to express their feelings, opinions, and emotional states. Billions of people worldwide use them daily to share what they think and feel in their posts. Amongst all social media available platforms, Facebook only contains around three billion personal accounts. In this work Reddit dataset is used to automatically detect mental illness from social media posts. This study is not only limited to early detection of already existing mental illness or disorder like depression and anxiety from social posts, but also and most importantly the study
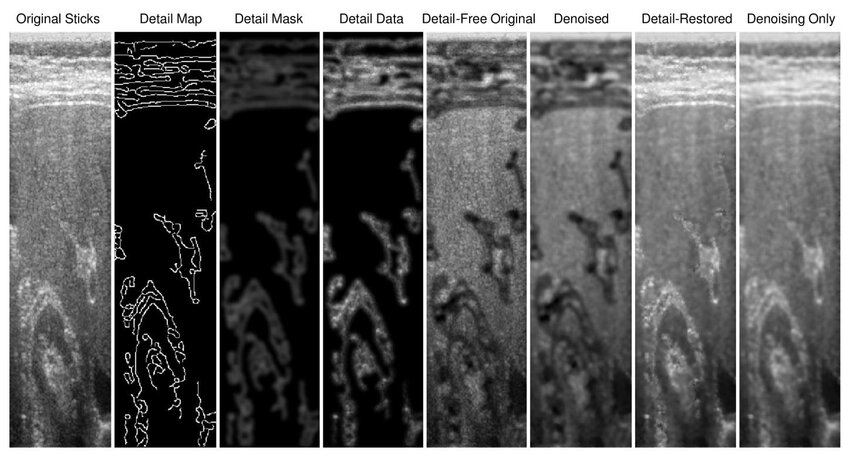
Edge Detail Preservation Technique for Enhancing Speckle Reduction Filtering Performance in Medical Ultrasound Imaging
—Ultrasound imaging is a unique medical imaging modality due to its clinical versatility, manageable biological effects, and low cost. However, a significant limitation of ultrasound imaging is the noisy appearance of its images due to speckle noise, which reduces image quality and hence makes diagnosis more challenging. Consequently, this problem received interest from many research groups and many methods have been proposed for speckle suppression using various filtering techniques. The common problem with such methods is that they tend to distort the edge detail content within the image and

Rice Plant Disease Detection and Diagnosis Using Deep Convolutional Neural Networks and Multispectral Imaging
Rice is considered a strategic crop in Egypt as it is regularly consumed in the Egyptian people’s diet. Even though Egypt is the highest rice producer in Africa with a share of 6 million tons per year [5], it still imports rice to satisfy its local needs due to production loss, especially due to rice disease. Rice blast disease is responsible for 30% loss in rice production worldwide [9]. Therefore, it is crucial to target limiting yield damage by detecting rice crops diseases in its early stages. This paper introduces a public multispectral and RGB images dataset and a deep learning pipeline
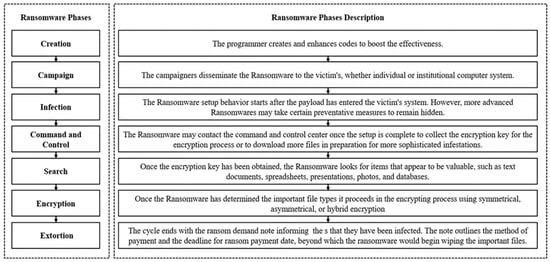
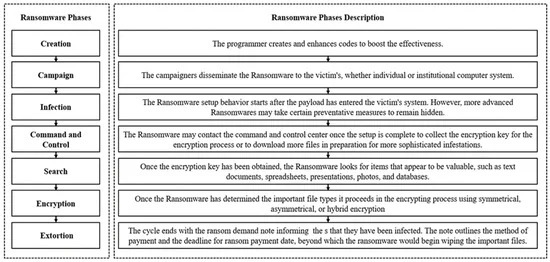
A New Scheme for Ransomware Classification and Clustering Using Static Features
Ransomware is a strain of malware that disables access to the user’s resources after infiltrating a victim’s system. Ransomware is one of the most dangerous malware organizations face by blocking data access or publishing private data over the internet. The major challenge of any entity is how to decrypt the files encrypted by ransomware. Ransomware’s binary analysis can provide a means to characterize the relationships between different features used by ransomware families to track the ransomware encryption mechanism routine. In this paper, we compare the different ransomware detection

An Evaluation of Time Series-Based Modeling and Forecasting of Infectious Diseases Progression using Statistical Versus Compartmental Methods
As a case study for our research, COVID-19, that was caused by a unique coronavirus, has substantially affected the globe, not only in terms of healthcare, but also in terms of economics, education, transportation, and politics. Predicting the pandemic's course is critical to combating and tracking its spread. The objective of our study is to evaluate, optimize and fine-Tune state of the art prediction models in order to enhance its performance and to automate its function as possible. Therefore, a comparison between statistical versus compartmental methods for time series-based modeling and
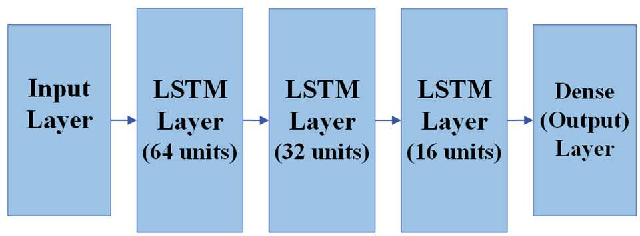
Multi-Band Radio Frequency Energy Predictor for Advanced Energy Harvesting Cellular Bands Systems
Radio Frequency (RF) energy harvesting has been employed to power wireless devices. Nevertheless, RF energy harvesting encounters restrictions regarding the quantity of power it can harvest depending on signal accessibility. As a result, accurately predicting energy levels becomes crucial for enhancing the performance of energy harvesting circuits. Most research efforts have concentrated on enhancing power harvesting policies or theoretically estimating the energy obtained through RF energy harvesting. Moreover, the existing literature has primarily focused on single-band prediction approaches
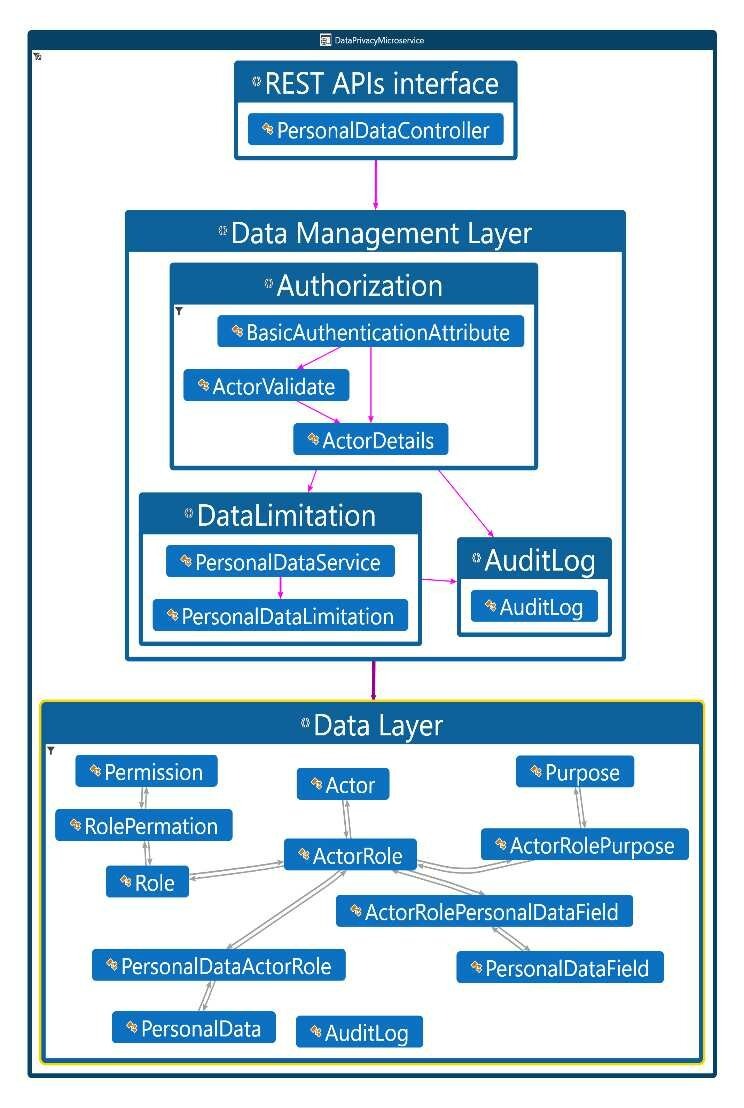
Privacy by Design: A Microservices-Based Software Architecture Approach
Data privacy regulations have increased significantly recently. As a result, privacy by design (PbD) has become a critical consideration for enterprises that handle personal data. PbD is no longer a plain principle. Rather than that, the General Data Protection Regulation (GDPR) addresses PbD as a required legal requirement for controllers who may face fines for non-compliance with the GDPR. In this paper, we propose a practical solution, 'PbD Microservice,' that can help organizations to achieve privacy regulatory compliance. We will focus on GDPR, one of the most important regulations that
Ransomware Clustering and Classification using Similarity Matrix
Ransomwares are amongst the most dangerous malwares that face and affect any business by restricting data access or leaking sensitive information over the internet. Ransomwares binary analysis can provide a way to define the relationships between distinct features employed by ransomware families. Malware classification and clustering systems offer an effective malware indexing with search functionalities, similarity checking, samples classification and clustering. Most studies focus on the static and dynamic features extraction, machine and deep learning or visualization techniques used to